Degraded performance on Notifications and Job Dispatches
Postmortem
Final report: Degraded performance on notifications and job dispatches
Executive Summary
From January 30th till February 6th 2023 we experienced degraded performance across our system. Primarily this impacted notification latency; only an estimated 85% of notifications were delivered within our internal 10 minute target during this week.
We also saw minor delays in the time it took to dispatch Jobs to customer agents (up to 70 seconds for about 6 hours), increased latency updating build statuses (up to 10 minutes for 8 hours) and sluggish web response times.
Our subsequent investigation has highlighted numerous areas in which we can improve our systems and processes in order to better recognise and mitigate performance issues. While we recognised this specific performance issue as early as November 2021, for many reasons we failed to implement sufficient mitigations in time. Efforts are already underway to make our system design more resilient, uplift team capabilities and clarify responsibilities in order to make our response more effective in the future.
Key Takeaways
Our method of measuring and reacting to database load growing over the long term, such as through database load alerts, wasn’t effective in preventing this incident.
- Work to shift some workloads to a read replica in 2022 was de-prioritised in favour of partitioning our biggest table (the Jobs table) which did not realise its expected performance benefits.
- Work started in December 2022 to cache notification queries wasn’t ready early enough to mitigate this incident.
- We continued to increase the threshold of our database load alert because it was having no customer impact. When database load was so high that it did have customer impact the threshold was too high to trigger an alert.
Efforts to improve database performance through partitioning were ineffective and in some cases made performance worse. This proved to be an expensive distraction which reduced our capacity to work on other, more effective, performance projects.
We have more work to do to make our teams truly cross-functional, so that the team that owns a particular feature has the capabilities to effectively manage it.
Our asynchronous task execution architecture contributed to the length and complexity of this incident, by facilitating runaway database load.
Actions
Since this incident we have already completed numerous tasks, including separating Builds and Jobs tables from Organisations and Users. This has further improved database load headroom and we are progressing many of the tasks below:
- Create internal Service Level Objectives for notification latency. This work is scheduled to be completed in the next month.
- Support product delivery teams to go on-call to level up their operational skills. This work will begin this month.
- Rolling out build retention to all customers: This will reduce the size of our largest tables and potentially reduce the total size of the database by up to 60%, without ever touching recent activity in your pipelines. This work is in progress and will be rolled out to customers gradually over the next few months.
- Migrate remaining notifications to use a read replica. This work is scheduled to be completed in the current quarter.
- Sharding our pipelines database. This allows us to manage database capacity much more effectively, and reduce the size and load on individual database instances. This derisks the most significant scaling challenges and minimises blast radius. This is scheduled to be completed before the middle of the year.
- Assign clear ownership of our asynchronous task execution system (Sidekiq) and review system architecture to prevent runaway database load. This work is scheduled for the second half of 2023.
- Investigate fully isolated customer infrastructure for Buildkite. This would allow us to move individual customers to a fully isolated Buildkite control plane, physically separated down to the AWS account level. This capability is currently being scoped.
- Improving our Incident Response processes, including customer communications and roles & responsibilities. This work is scheduled to be completed in the next two months.
—------------------------------------------------------------------------------------------------------------------------
Interim report: Degraded performance on notifications and job dispatches
We would like to share this interim report on the degraded performance for notifications and job dispatches you experienced at the start of this month.
Summary
From Tuesday 31st January until Monday 6th of February, Buildkite experienced varying levels of degraded performance of our asynchronous tasks.
The key contributing factor was increased load on our primary database.
The primary customer impacts were:
Job Dispatches: Buildkite Agents waiting for pipeline jobs to be assigned via the Agent API saw delays of up to 70 seconds between the 1st and 2nd of February.
Build status updates: Delays in this result in builds taking longer to reflect their final status and have a knock on effect to subsequent notifications being sent out. We saw delays of up to 12 minutes between the 31st of January and 3rd of February.
Commit statuses: Reflecting a green tick on GitHub and other version control systems. This is often used as a permissions gate to allow merging a Pull Request. Between 30th of January and 3rd of February we saw delays of up to 52 minutes, where normally we see sub-second latency.
Job notifications: Used to reflect step status in Github. Some customers use this to assign pipeline jobs to agents using the acquire job feature, resulting in jobs taking longer to start. Between January 30th and February 6th delays of up to 5 hours were experienced.
See Appendix for a full breakdown of impact.
We implemented a series of mitigations between January 31st and February 6th to reduce load on our primary database, including moving some query workloads to a replica database. This reduced contention and load on the primary database, which in turn caused performance to return to satisfactory levels.
Technical Background
To explain how these delays occurred we have to explain first in a bit more detail how builds work. The fundamental building block for pipelines is a job and a build typically consists of many jobs. Here’s a simplified flow chart of Job and Build state machines.
Build states:
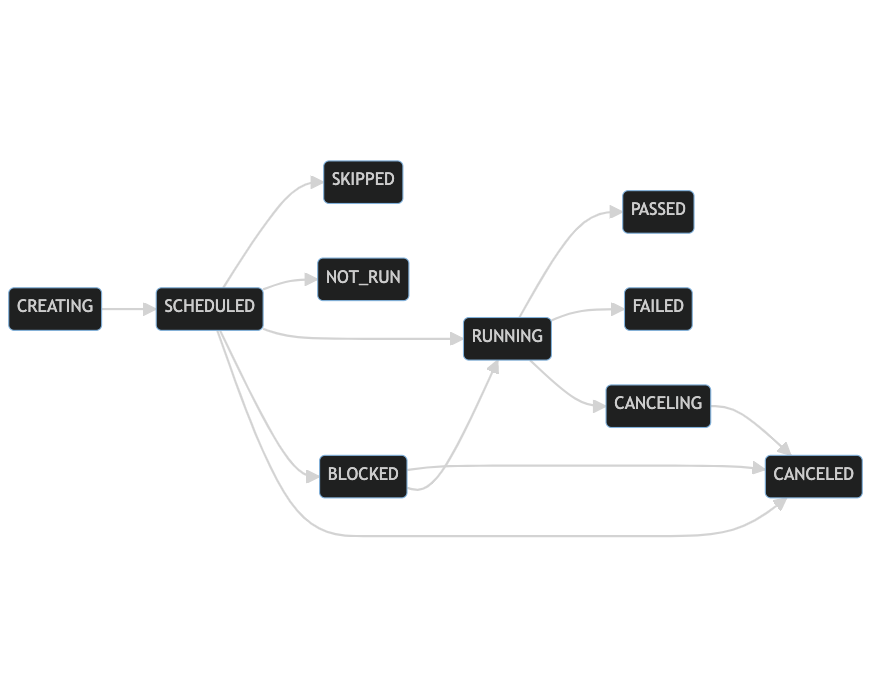
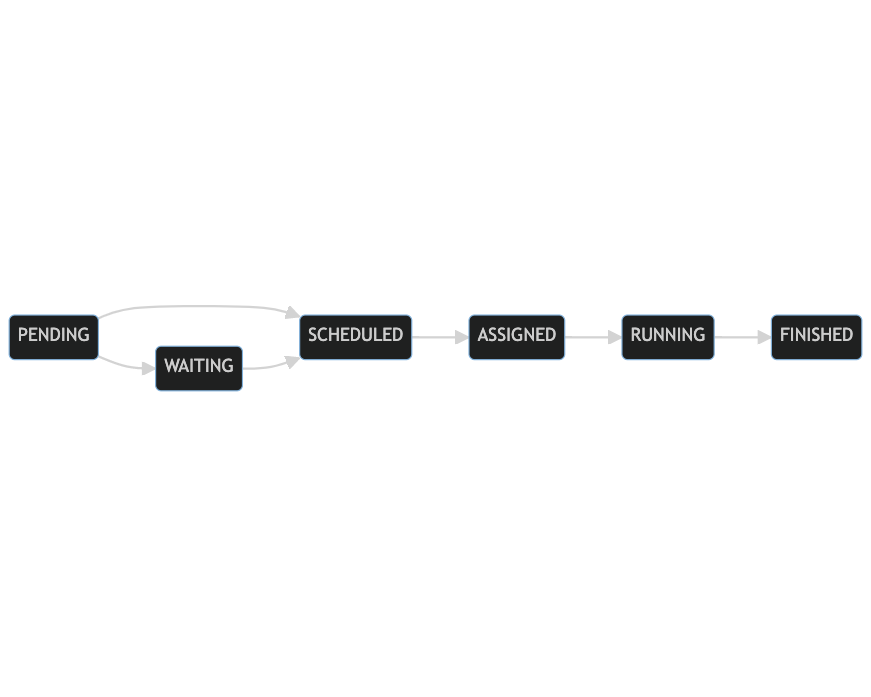
Some of these transitions happen synchronously when an API request is made, for instance when an agent reports a job as finished we immediately update the database record to reflect this. Others, such as assigning jobs to an agent or transitioning a running build to Passed or Failed, happen asynchronously.
Regardless of whether the transition happens synchronously or asynchronously, we schedule an asynchronous task to fire off any notifications from that job or build. This task checks to see what notifications are configured and then schedules more tasks to actually send the corresponding webhooks. We send on average 50-100 notifications per build, depending on the time of day. Generating each notification then creates many SQL queries.
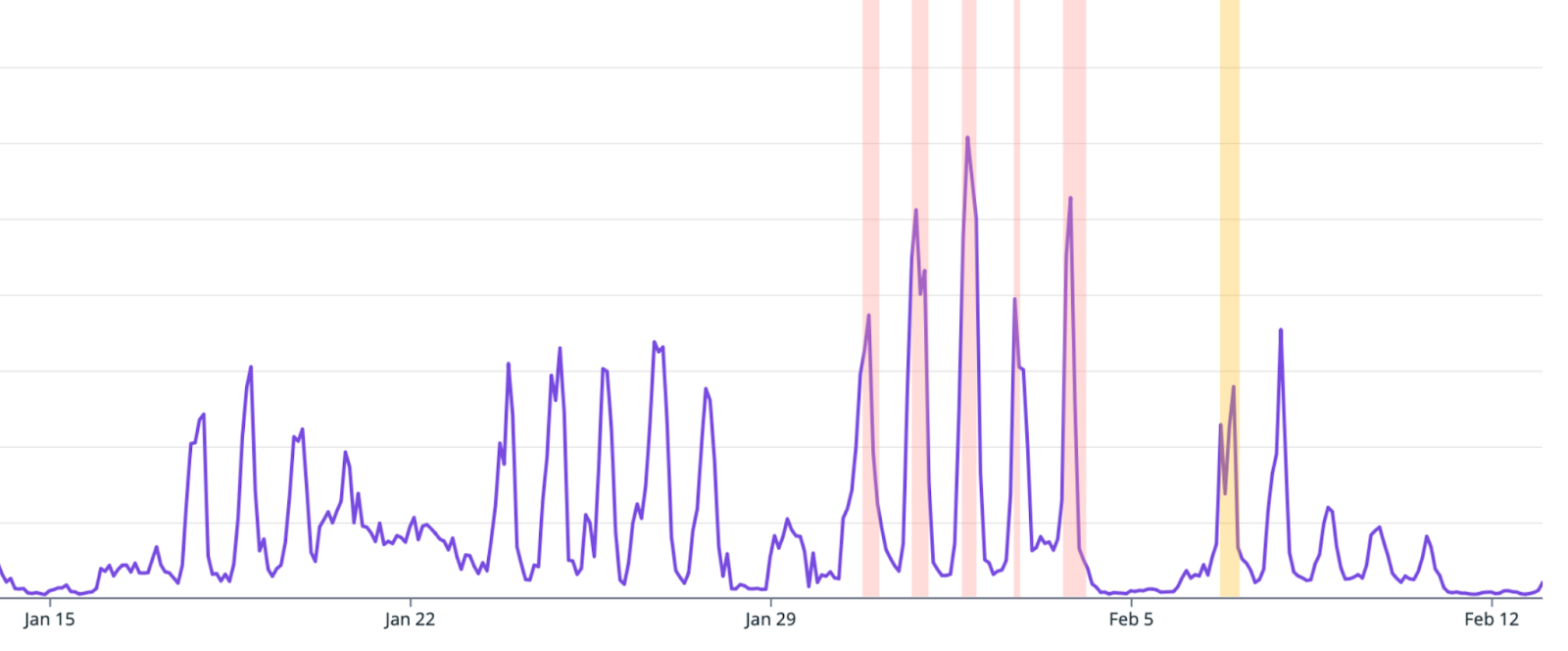
Over the course of the week we saw our highest ever load in terms of pipeline jobs (4% higher than our previous highest hourly load) and volume of outbound notifications.
At times of peak job creation, normally mid-morning PST, the system suffered a severe performance cliff. As we failed to keep up with the rate of notifications being sent, a backlog accumulated. This resulted in higher attempted concurrency of jobs and therefore database contention, which in turn slowed down our throughput. This reinforcing feedback cycle meant once we experienced the performance cliff it often took us many hours to recover.
Mitigations
Our first priority was to limit customer impact by splitting notifications tasks from other higher priority tasks, giving us the capability to disable specific types of notifications and understand better the impact this had.
Interim Conclusion
We continue to work on understanding how we came to be in this situation and are devising strategies to prevent it from happening again.
At Buildkite, we value honesty and transparency, especially when we fall short of expectations. While we understand that this recent experience may have been frustrating for you, I want to assure you that our engineering and support teams went above and beyond to manage and resolve this complex incident. As someone new to Buildkite it was really great to see them work, and how they problem-solved under pressure. We are confident that we have addressed the issue at hand and are taking steps to ensure it doesn't happen again.
We're currently in the process of gathering all the necessary information for a full incident report, which will include a detailed account of how the events unfolded, as well as a roadmap outlining our plans for future capacity and scalability mitigations. This report will be completed within the coming weeks and will be shared with you.
Thank you for being a Buildkite customer.
Daniel Vydra
CTO, Buildkite
Appendix
Customer Impact (UTC)
Job dispatch (Assigning jobs to agents via the agent API. Delays in this result in jobs taking longer to start):
2023-02-01 19:25 - 2023-02-02 01:30 Dispatch times vary from 30-70 seconds
2023-02-02 18:22 - 18:38 Dispatch times spike up to 70 seconds
Build status updates (Reflecting Job finished in the UI and API. Delays in this result in builds taking longer to reflect their final status and subsequent notifications being sent.):
2023-01-31 19:40 - 2023-02-01 00:20 Latency remains above 5 minutes and spikes as high as 12 minutes
2023-02-01 19:00 - 2023-02-01 22:30 Latency varies between 1 and 5 minutes
2023-02-03 18:30 - 22:20 Latency varies between 5 seconds (within normal levels) and 60 seconds (above normal levels)
Github commit status notifications (Reflecting a green tick on Github. This is often used as a permissions gate to allow users to merge a Pull Request. Delays in this often result in not being able to deploy their changes as quickly):
2023-01-30 21:12 - 23:34 Latency of up to 50 minutes
2023-01-31 19:47 - 2023-02-01 02:30 Latency remains above 5 minutes and spikes as high as 20 minutes
2023-02-01 19:00 - 2023-02-02 01:50 Latency spikes up to 52 minutes
2023-02-02 18:23 - 18:40 Latency spikes up to 9 minutes
2023-02-03 22:15 - 22:55 Latency spikes up to 30 minutes
Job notifications (Used to reflect step status in Github. Some customers use this to assign jobs to agents using the acquire job feature, resulting in jobs taking longer to start)
2023-01-30 21:12 - 23:34 Latency of up to 50 minutes
2023-01-31 19:47 - 2023-02-01 02:30 Latency remains above 5 minutes and spikes as high as 20 minutes
2023-02-01 19:00 - 2023-02-02 01:50 Latency spikes up to 52 minutes
2023-02-02 18:23 - 19:23 Latency spikes up to 9 minutes
2023-02-03 19:05 - 2023-02-04 03:40 Latency spikes up to 5 hours
2023-02-06 19:23 - 23:05 A small number of notifications are delayed by up to 26 minutes.
Agent status update (When an agent stops responding to our heartbeats we mark it as lost and any jobs assigned to it are marked failed. Customers may manually or automatically retry jobs in this state. Delays in this feature result in jobs taking longer to be marked as failed and turn around times to correct this being longer)
2023-01-31 17:30 - 2023-02-01 02:00 Latency peaks at 5 minutes
2023-01-01 17:30 - 2023-02-02 02:00 Latency peaks at 5 minutes
2023-02-02 18:00 - 2023-02-02 20:00 Latency peaks at 4 minutes
2023-02-03 18:30 - 2023-02-03 22:00 Latency peaks at 5 minutes
Resolved
We continue to investigate and work on longer-term mitigations for the ongoing issues.